pgBackRest is a popular backup and restore tool for PostgreSQL, known for easily handling even the largest databases and workloads. It’s packed with powerful features, but all that flexibility can sometimes feel a bit overwhelming.
In my earlier posts, I showed how to take backups from a standby server and how to set up a dedicated backup host. But there’s another great feature we haven’t explored yet: pgBackRest can store backups in cloud storage like S3, Azure, or Google Cloud.
Most people choose one option: either a backup host or cloud storage. But did you know you can use both at the same time? This gives you even more flexibility in your backup strategy.
Let’s pick up where we left off. We’ve got a PostgreSQL cluster with a primary server (pg1), a standby server (pg2), and a backup server (repo1) storing backups and WAL archives on an NFS mount. Today, we’ll take it a step further by adding an S3 bucket to the setup :-)
Example setup: S3 bucket with a repository host
Initial situation
As a reminder, here’s the initial situation and configuration.
pg1 is our primary:
[postgres@pg1 ~]$ ps -o pid,cmd fx
PID CMD
764 /usr/pgsql-16/bin/postgres -D /var/lib/pgsql/16/data/
814 \_ postgres: logger
824 \_ postgres: checkpointer
825 \_ postgres: background writer
834 \_ postgres: walwriter
835 \_ postgres: autovacuum launcher
836 \_ postgres: archiver last was 000000010000000000000060
837 \_ postgres: logical replication launcher
841 \_ postgres: walsender replicator 192.168.121.66(38334) streaming 0/610001C0
pg2 is our standby server:
[postgres@pg2 ~]$ ps -o pid,cmd fx
PID CMD
744 /usr/pgsql-16/bin/postgres -D /var/lib/pgsql/16/data/
821 \_ postgres: logger
831 \_ postgres: checkpointer
832 \_ postgres: background writer
833 \_ postgres: startup recovering 000000010000000000000061
870 \_ postgres: walreceiver streaming 0/610001C0
The /etc/pgbackrest.conf configuration is exactly the same on both nodes:
[global]
repo1-host=repo1
repo1-host-user=pgbackrest
log-level-console=info
log-level-file=detail
compress-type=zst
[mycluster]
pg1-path=/var/lib/pgsql/16/data
repo1 is our dedicated backup host and there’s one full backup in the repository:
[pgbackrest@repo1 ~]$ pgbackrest info
stanza: mycluster
status: ok
cipher: none
db (current)
wal archive min/max (16): 000000010000000000000062/000000010000000000000062
full backup: 20241127-125209F
timestamp start/stop: 2024-11-27 12:52:09+00 / 2024-11-27 12:52:13+00
wal start/stop: 000000010000000000000062 / 000000010000000000000062
database size: 1.5GB, database backup size: 1.5GB
repo1: backup size: 70.3MB
Here’s the /etc/pgbackrest.conf configuration for this node:
[global]
repo1-path=/shared/pgbackrest
repo1-retention-full=4
repo1-bundle=y
repo1-block=y
start-fast=y
log-level-console=info
log-level-file=detail
delta=y
process-max=2
compress-type=zst
backup-standby=y
[mycluster]
pg1-path=/var/lib/pgsql/16/data
pg1-host=pg1
pg1-host-user=postgres
pg2-path=/var/lib/pgsql/16/data
pg2-host=pg2
pg2-host-user=postgres
The repository repo1-path=/shared/pgbackrest is currently an NFS mount point.
Let’s adjust this setting to point to an S3 bucket named myversionedbucket with the following configuration:
repo1-path=/demo-repo
repo1-type=s3
repo1-s3-bucket=myversionedbucket
repo1-s3-key=accessKey1
repo1-s3-key-secret=verySecretKey1
repo1-s3-region=us-east-1
repo1-s3-endpoint=s3.us-east-1.amazonaws.com
As the new repository is empty, we need to initialize it and use the stanza-create command:
[pgbackrest@repo1 ~]$ pgbackrest --stanza=mycluster stanza-create
INFO: stanza-create for stanza 'mycluster' on repo1
INFO: stanza-create command end: completed successfully
Then, check that the archiving process is still functioning correctly. WAL archives should now be pushed from the primary to the S3 bucket. Remember, the archives are still routed through our dedicated backup host, as we haven’t changed the PostgreSQL node configurations!
[pgbackrest@repo1 ~]$ pgbackrest --stanza=mycluster check
INFO: check repo1 configuration (primary)
INFO: check repo1 archive for WAL (primary)
INFO: WAL segment 000000010000000000000063 successfully archived to '...' on repo1
INFO: check command end: completed successfully
Let’s take a backup now:
[pgbackrest@repo1 ~]$ pgbackrest --stanza=mycluster backup --type=full
INFO: backup command begin ...
INFO: execute non-exclusive backup start:
backup begins after the requested immediate checkpoint completes
INFO: backup start archive = 000000010000000000000065, lsn = 0/65000028
INFO: wait for replay on the standby to reach 0/65000028
INFO: replay on the standby reached 0/65000028
INFO: check archive for prior segment 000000010000000000000064
INFO: execute non-exclusive backup stop and wait for all WAL segments to archive
INFO: backup stop archive = 000000010000000000000065, lsn = 0/65000100
INFO: check archive for segment(s) 000000010000000000000065:000000010000000000000065
INFO: new backup label = 20241127-135531F
INFO: full backup size = 1.5GB, file total = 1283
INFO: backup command end: completed successfully
Finally, here’s what our current setup looks like:
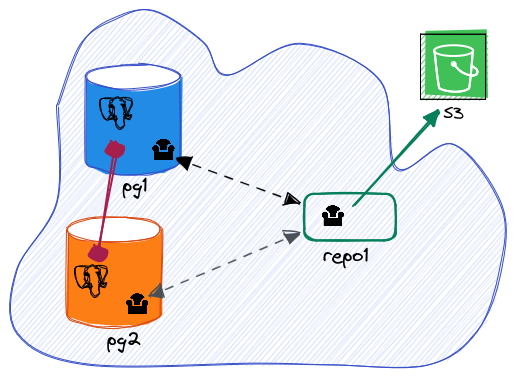
What happens if the repository host is down?
With repo1 down, the PostgreSQL nodes can’t reach the backup storage anymore…
[postgres@pg1 ~]$ pgbackrest info
stanza: [invalid]
status: error (other)
[UnknownError] remote-0 process on 'repo1' terminated unexpectedly
[255]: ssh: connect to host repo1 port 22: No route to host
It also means that the WAL archiver process is blocked:
[postgres@pg1 ~]$ psql -x -c "select * from pg_stat_archiver;"
-[ RECORD 1 ]------+-----------------------------------------
failed_count | 12
last_failed_wal | 000000010000000000000066
last_failed_time | 2024-11-27 13:58:16.547647+00
Obviously, you’re not triggering backups every 5 minutes, so having the repository host down for a while might not seem like a big issue at first. However, the magic of PostgreSQL’s Point-In-Time Recovery relies on continuous WAL archiving. If the archiver process gets blocked, PostgreSQL will start storing all the WAL files locally in its pg_wal directory until the issue is resolved. This can quickly lead to disk space problems and, in the worst-case scenario, bring your cluster down.
Thankfully, pgBackRest offers the archive-push-queue-max setting to help manage this situation. But why stop there? We can get creative and take advantage of pgBackRest’s flexibility by attaching the S3 bucket directly to the PostgreSQL nodes…
Attaching the S3 bucket directly to PostgreSQL nodes
As a reminder, on pg1 and pg2, the repository is currently defined as:
repo1-host=repo1
repo1-host-user=pgbackrest
We’ll replace these settings with the S3 bucket configuration:
repo1-path=/demo-repo
repo1-type=s3
repo1-s3-bucket=myversionedbucket
repo1-s3-key=accessKey1
repo1-s3-key-secret=verySecretKey1
repo1-s3-region=us-east-1
repo1-s3-endpoint=s3.us-east-1.amazonaws.com
This change allows us to view the repository content and unblock the archiver process:
[postgres@pg1 ~]$ pgbackrest info
stanza: mycluster
status: ok
cipher: none
db (current)
wal archive min/max (16): 000000010000000000000063/000000010000000000000065
full backup: 20241127-135531F
timestamp start/stop: 2024-11-27 13:55:31+00 / 2024-11-27 13:55:35+00
wal start/stop: 000000010000000000000065 / 000000010000000000000065
database size: 1.5GB, database backup size: 1.5GB
repo1: backup size: 70.3MB
[postgres@pg1 ~]$ pgbackrest --stanza=mycluster check
INFO: check repo1 configuration (primary)
INFO: check repo1 archive for WAL (primary)
INFO: WAL segment 000000010000000000000067 successfully archived to '...' on repo1
INFO: check command end: completed successfully
Now that we’ve connected the PostgreSQL nodes to the S3 bucket, we can trigger a backup from any node. On the primary server (pg1), let’s first add the pgBackRest backup configuration (as defined earlier on the repository host, repo1):
repo1-retention-full=4
repo1-bundle=y
repo1-block=y
start-fast=y
delta=y
process-max=2
Finally, trigger an incremental backup:
[postgres@pg1 ~]$ pgbackrest --stanza=mycluster backup --type=incr
INFO: backup command begin ...
INFO: last backup label = 20241127-135531F
...
INFO: backup command end: completed successfully
Here’s what our updated setup looks like:
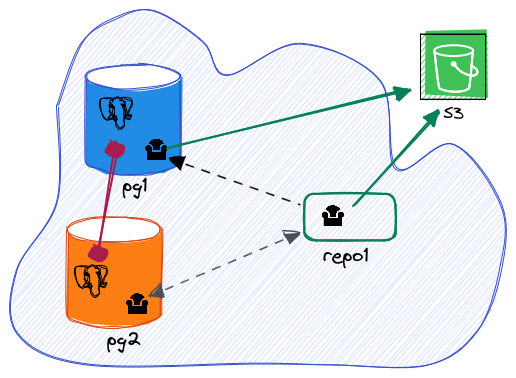
What happens when the repository host is back online?
Once the repository host is back online, it will regain access to the PostgreSQL nodes and can resume taking backups as usual. Since all nodes, including the repository host, point to the same repository location (the S3 bucket), pgBackRest will seamlessly pick up where it left off, ensuring smooth and uninterrupted operation.
Conclusion
Routing archiving directly to S3 helped avoid potential disk space issues on the PostgreSQL nodes caused by accumulating WAL files. It also introduced the flexibility to trigger backups from any node, ensuring the cluster remains operational even if one node fails.
However, from a security perspective, this setup exposes your S3 bucket’s content to all nodes, requiring careful management of access credentials. It also adds the responsibility of keeping configuration files synchronized when making changes, such as updating retention settings.
Additionally, if encryption is used, the key must be present on all nodes, further increasing the risk of exposure.
Ultimately, finding the right balance between security and availability is the key challenge, and pgBackRest’s flexibility helps you deal with it ;-)
Tweet